网络数据传输是我们日常开发中不可避免的问题,同时也是出现不确定性问题最多的地方。
本文介绍了网络数据传输的拥塞发生原因,以及在TCP中是如何控制拥塞、控制流量的。
什么是拥塞
当大量的分组进入通信子网,超出了网络的处理能力时,就会引起网络局部或整体性能下降,这种现象称为拥塞。拥塞常常使问题趋于恶化。
另一种对拥塞的解释,即对资源的需求超过了可用的资源。若网络中许多资源同时供应不足,网络的性能就要明显变坏,整个网络的吞吐量随之负荷的增大而下降。
拥塞的发生与不可避免
拥塞发生的主要原因
网络能够提供的资源不足以满足用户的需求,这些资源包括缓存空间、链路带宽容量和中间节点的处理能力。由于互联网的设计机制导致其缺乏“接纳控制”能力,因此在网络资源不足时不能限制用户数量,而只能靠降低服务质量来继续为用户服务,也就是“尽力而为”的服务。
不可避免
拥塞其实是一个动态问题,我们没有办法用一个静态方案去解决,从这个意义上来说,拥塞是不可避免的。
拥塞控制和流量控制的差别
所谓拥塞控制就是防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能承受现有的网络负荷。
流量控制往往指的是点对点通信量的控制,是个端到端的问题。流量控制所要做的就是控制发送端发送数据的速率,以便使接收端来得及接受。
TCP拥塞控制
为什么需要TCP拥塞控制
由于TCP采用了超时重传机制,如果拥塞不加以控制,将导致大量的报文重传,并再度引起大量的数据报丢弃,直到整个网络瘫痪。这种现象称为拥塞崩溃。
在网络实际的传输过程中,会出现拥塞的现象,网络上充斥着非常多的数据包,但是却不能按时被传送,形成网络拥塞,其实就是和平时的堵车一个性质了。TCP设计中也考虑到这一点,使用了一些算法来检测网络拥塞现象,如果拥塞产生,便会调整发送策略,减少数据包的发送来缓解网络的压力。
拥塞控制:防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提:网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机、路由器,以及与降低网络传输性能有关的所有因素。
TCP的流量控制
早期的TCP协议只有基于窗口的流控制(flow control)机制,我们简单介绍一下,并分析其不足。
在TCP中,为了实现可靠性,发送方发出一个数据段之后要等待接收方相应的确认信息,而不是直接发送下一个分组。
具体的技术是采用滑动窗口,以便通信双方能够充分利用带宽。滑动窗口允许发送方在收到接收方的确认之前发送多个数据段。窗口大小决定了在收到目的地确认之前,一次可以传送的数据段的最大数目。窗口大小越大,主机一次可以传输的数据段就越多。当主机传输窗口大小数目的数据段后,就必须等收到确认,才可以再传下面的数据段。
例如,若视窗的大小为1,则传完数据段后,都必须经过确认,才可以再传下一个数据段;当窗口大小等于3时,发送方可以一次传输3个数据段,等待对方确认后,再传输下面三个数据段。
窗口的大小在通信双方连接期间是可变的,通信双方可以通过协商动态地修改窗口大小。
在TCP的每个确认中,除了指出希望收到的下一个数据段的序列号之外,还包括一个窗口通告,通告中指出了接收方还能再收多少数据段(我们可以把通告看成接收缓冲区大小)。如果通告值增大,窗口大小也相应增大;通告值减小,窗口大小也相应减小。
但是我们可以发现,接收端并没有特别合适的方法来判断当前网络是否拥塞,因为它只是被动得接收,不像发送端,当发出一个数据段后,会等待对方得确认信息,如果超时,就可以认为网络已经拥塞了。
所以,改变窗口大小的唯一根据,就是接收端缓冲区的大小了。
流量控制作为接收方管理发送方发送数据的方式,用来防止接收方可用的数据缓存空间的溢出。
流控制是一种局部控制机制,其参与者仅仅是发送方和接收方,它只考虑了接收端的接收能力,而没有考虑到网络的传输能力;
而拥塞控制则注重于整体,其考虑的是整个网络的传输能力,是一种全局控制机制。正因为流控制的这种局限性,从而导致了拥塞崩溃现象的发生。
TCP拥塞控制的四大过程
TCP的拥塞控制由4个核心算法组成:“慢启动”(Slow Start)、“拥塞避免”(Congestion voidance)、“快速重传 ”(Fast Retransmit)、“快速恢复”(Fast Recovery)。
为了方便起见,把发送端叫做client,接收端为server,每个segment长度为512字节,阻塞窗口长度为cwnd(简化起见,下面以segment为单位),sequence number为seq_num,acknowledges number为ack_num。通常情况下,TCP每接收到两个segment,发送一个ack。
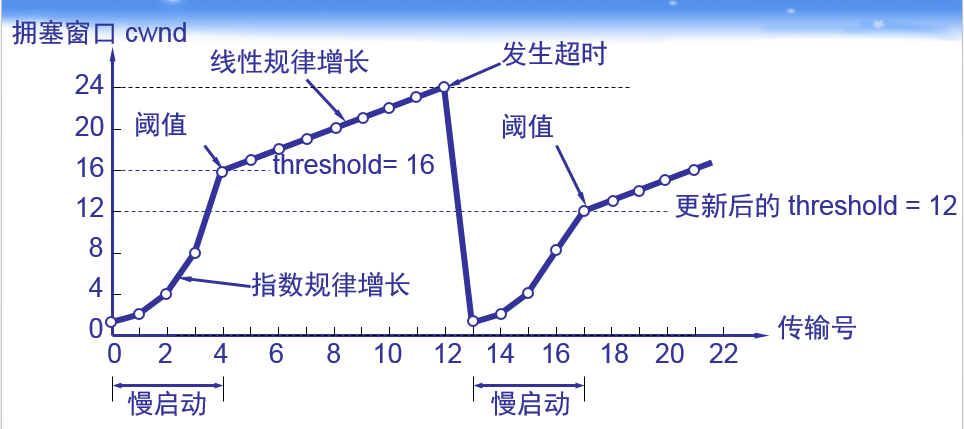
慢启动
早期开发的TCP应用在启动一个连接时会向网络中发送大量的数据包,这样很容易导致路由器缓存空间耗尽,网络发生拥塞,使得TCP连接的吞吐量急剧下降。
由于TCP源端一开始并不知道网络资源当前的利用状况,因此新建立的TCP连接不能一开始就发送大量数据,而只能逐步增加每次发送的数据量,以避免上述现象的发生,这里有一个“学习”的过程。
假设client要发送5120字节到server,慢启动过程如下:
- 初始状态,cwnd=1,seq_num=1;client发送第一个segment。
- server接收到512字节(一个segment),回应ack_num=513。
- client接收ack(513),cwnd=1+1=2;现在可以一次发送2个数据段而不必等待ack。
- server接收到2个segment,回应ack_num=513+512*2=1537。
- client接收ack(1537),cwnd=2+1;一次发送3个数据段。
- server接收到3个segment,回应2个ack,分别为ack_num=1537+1024=2561和ack_num=2561+512=3073。
- client接收ack(2561)和ack(3073),cwnd=3+2=5;一次可以发送5个数据段,但是只用4个就满足要求了。
- server接收到4个segment,回应2个ack,分别为4097,5121
- 已经发送5120字节,任务完成!
总结一下:
当建立新的TCP连接时,拥塞窗口(congestion window,cwnd)初始化为一个数据包大小。源端按cwnd大小发送数据,每收到一个ACK确认,cwnd就增加一个数据包发送量。
- 慢启动算法是一个在连接上发起数据流的方法
- 慢启动过程:
- 初始时将拥塞窗口的大小初始为一个MSS
- 每次收到一个报文段的确认时,发送方将拥塞窗口增大一个MSS,并发送两个最大长度的报文段
- 两个报文段被确认后,则发送方对每个报文段的确认增加一个MSS,使得拥塞窗口大小变为4个MSS
- 这样每经过一个RTT,发送速率就翻倍。
- 因此,慢启动阶段以指数增长
- 慢启动的结束
- 当出现一个由超时指示的丢包时间,发送方将cwnd设置为1,并重新开始慢启动
拥塞避免
可以想象,如果按上述慢启动的逻辑继续下去而不加任何控制的话,必然会发生拥塞,引入一个慢启动阈值ssthresh的概念,当cwnd < ssthresh的时候,tcp处于慢启动状态,否则,进入拥塞避免阶段。
拥塞避免的主要思想是加法增大,也就是cwnd的值不再指数级往上升,开始加法增加。此时当窗口中所有的报文段都被确认时,cwnd的大小加1,cwnd的值就随着RTT开始线性增加,这样就可以避免增长过快导致网络拥塞,慢慢的增加调整到网络的最佳值。
通常,ssthresh初始化为 64 Kbytes。
当cwnd = 65024 + 512 = 65536,进入拥塞避免阶段,假设此时seq_num = 101024
- client一次发送cwnd,但是先考虑头两个segment。
- server回应ack_num = 102048
- client接收到ack(102048),cwnd = 65536 + [(512 * 512) /65536] = 65536 + 4 = 65540,也就是说,每接到一个ack,cwnd只增加4个字节
- client发送一个segment,并开启ack timer,等待server对这个segment的ack,如果超时,则认为网络已经处于拥塞状态,则重设慢启动阀值ssthresh=当前cwnd/2=65536/2=32768,并且,立刻把cwnd设为1,很极端的处理!
- 此时,cwnd < ssthresh,所以,恢复到慢启动状态。
总结一下:
如果当前cwnd达到慢启动阀值,则试探性的发送一个segment,如果server超时未响应,TCP认为网络能力下降,必须降低慢启动阀值,同时,为了避免形势恶化,干脆采取极端措施,把发送窗口降为1。
- 拥塞避免算法是一种处理丢失分组的方法(当到达中间路由器的极限时,分组将被丢弃)
- 拥塞避免过程:
- 进入拥塞避免时,拥塞窗口的值大约是上次遇到拥塞时值的一半
- 每个RTT只将拥塞窗口的值增加1个MSS
- 拥塞避免结束条件:
- 超时或丢包
快重传和快恢复
标准的重传,client会等待RTO时间再重传,但有时候,不必等这么久也可以判断需要重传,
快重传
例如:client一次发送8个segment,seq_num起始值为100000,但是由于网络原因,100512丢失,其他的正常,则server会响应4个ack(100512)(为什么呢,tcp会把接收到的其他segment缓存起来,ack_num必须是连续的),这时候,client接收到四个重复的ack,它完全有理由判断100512丢失,进而重传,而不必傻等RTO时间了。
快恢复
我们通常认为client接收到3个重复的ack后,就会开始快速重传,但是,如果还有更多的重复ack呢,如何处理?这就是快速恢复要做的,事实上,我们可以把快速恢复看作是快速重传的后续处理,它不是一种单独存在的形态。
以下是具体的流程:
假设此时cwnd = 70000,client发送4096字节到server,也就是8个segment,起始seq_num = 100000:
- client发送seq_num = 100000。
- seq_num =100512的segment丢失。
- client发送seq_num = 101024。
- server接收到两个segment,它意识到100512丢失,先把收到的这两个segment缓存起来。
- server回应一个ack(100512),表示它还期待这个segment 。
- client发送seq_num = 101536 。
- server接收到一个segment,它判断不是100512,依旧把收到的这个segment缓存起来,并回应ack(100512) 。
- 以下同6、7,直到client收到3个ack(100512),进入快速重发阶段。
- 重设慢启动阀值ssthresh=当前cwnd/2=70000/2=35000 。
- client发送seq_num = 100512,以下,进入快速恢复阶段。
- 重设cwnd = ssthresh + 3 segments =35000 + 3 * 512 = 36536,之所以要加3,是因为我们已经接收到3个ack(100512)了,根据前面说的,每接收到一个ack,cwnd加1。
- client接收到第四个、第五个ack(100512),cwnd=36536+2 * 512=37560。
- server接收到100512,响应ack_num = 104096
- 此时,cwnd>ssthresh,进入拥塞避免阶段。
执行的条件及过程
当收到3个或3个以上的重复ACK时,就非常有可能是一个报文段丢失了。于是我们就重传丢失的数据报文段,而不等待超时定时器溢出。这就是快速重传。接下来执行的不是慢启动,而是拥塞避免,这就是快速恢复。
原因
没有执行慢启动的原因是由于收到的重复的ACK不仅仅告诉我们一个分组丢失了。由于接收方只有在收到另一个报文段时才会产生重复的ACK,而该报文段已经离开网络并进入了接收方的缓存。也就是说在收发两端之间仍然有流动的数据,而我们不想执行慢启动来突然减少数据流。
牛客网Java刷题知识点之拥塞发生的主要原因、TCP拥塞控制、TCP流量控制、TCP拥塞控制的四大过程(慢启动、拥塞避免、快速重传、快速恢复)